
Paradise Lost Data Visualization and Sentiment Analysis
“Farewell happy fields
Where joy for ever dwells: Hail horrors, hail
Infernal world, and thou profoundest Hell
Receive thy new possessor: One who brings
A mind not to be changed by place or time.
The mind is its own place, and in itself
Can make a Heaven of Hell, a Hell of Heaven.”
Book I, Lines 249-255

The language of Milton’s Paradise Lost invites an exploration of unique English composition and poetic style. His language is not Middle English, nor is it artificially archaicised like Spenser, nor is it exactly a King James biblical style. T.S. Elliot remarks that “Milton writes English like a dead language”. This lends the work a unique challenge to analysis and understanding by natural language processing.
Sentiment analysis is the computational study of opinions, attitudes, and emotions expressed in (written) language, and is commonly used in natural language processing to determine the polarity of a text as expressing positive or negative sentiment. This project follows as: three sentiment analysis tools — VADER; TextBLOB; NRC — are applied to a spelling-normalized editin of John Milton’s Paradise Lost and are compared for their respective sentiment metric scores. Each analyses’ performance is averaged and given.
VADER’s results (measured for: neg(ative); neu(tral); pos(itive); compound) follow as:
| neg | neu | pos | compound | |||||
|---|---|---|---|---|---|---|---|---|
| mean | 0.16 | 0.58 | 0.26 | 0.67 | ||||
| std | 0.06 | 0.04 | 0.05 | 0.78 | ||||
| min | 0.07 | 0.52 | 0.20 | -1.00 | ||||
| max | 0.26 | 0.65 | 0.33 | 1.00 |
TextBLOB’s results (measured for: polarity; objectivity) follow as:
| polarity | subjectivity | |||
|---|---|---|---|---|
| mean | 0.14 | 0.53 | ||
| std | 0.06 | 0.01 | ||
| min | 0.05 | 0.51 | ||
| max | 0.23 | 0.55 |
NRC’s reults (measured for: fear; anger; anticipation; trust; surprise; positive; negative; sadness; disgust; joy) follow as:
| fear | anger | anticipation | trust | surprise | positive | negative | sadness | disgust | joy | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| mean | 0.11 | 0.07 | 0.10 | 0.12 | 0.04 | 0.20 | 0.15 | 0.07 | 0.05 | 0.09 | ||||||||||
| std | 0.03 | 0.02 | 0.02 | 0.03 | 0.01 | 0.04 | 0.03 | 0.02 | 0.01 | 0.02 | ||||||||||
| min | 0.06 | 0.04 | 0.07 | 0.08 | 0.03 | 0.13 | 0.09 | 0.04 | 0.02 | 0.06 | ||||||||||
| max | 0.15 | 0.10 | 0.12 | 0.17 | 0.05 | 0.27 | 0.19 | 0.11 | 0.08 | 0.13 |
Across each sentiment analysis, we see a general trend towards an overall positivity score. Polarity extrema in TextBLOB relate as crossover points in VADER and NRC for positivity and negativity metrics, and do so such that minima of polarity scores in TextBLOB correlate with increasing negative scores and decreasing positivy scores in VADER and NRC, and vise versa. These emotional points in the narrative occur at the regions of Books I to III, Book VI, and Books IX to XI.
The visualization and sentiment analyses used in this project are available here.
Introduction
Paradise Lost is a sprawling English-language epic poem in blank verse by the 17th-century English poet John Milton. First published in ten books in 1667, the twelve book version (which is used in this analysis) came out in 1674. THe poem is (largely) a retelling of the third chapter of Genesis with the addition of flashbacks to Satan’s rebellion in heaven as well as visions of later parts of the Bible. The poem was famously illustrated by French artist Gustave Doré, whose work is featured above.
The unique language of the poem offers a playground for NLP tasks such as sentiment analysis (as in this project); see here for an etymological study of Milton’s language in the poem. The goal of this project is twofold: 1) practice with data exploration and visualization 2) **classify sentiment across various NLP sentiment analysis tools. This project follows from the work of NBrisbon on The Silmarillion, and so frequent comparison are made. The question remains: what sentiment analysis tools yield intuitive scores for sentiment?
Methods
A searchable etext of Paradise Lost is available here, in which “Milton’s archaic spelling has been modernized to faciltate search”. Each book of the poem is saved as a text that is accessed and saved to a dataframe which are cleaned for stopwords, punctuation, and contractions, and is otherwise normalized to facilitate meaningful comparisons.
Data visualization includes meaningful graphical representations of information in the text: POS frequencies; wordcloud representations; n-gram (mono-, bi-, tri-gram); average word length represented as probability density; lexical density (including normalization). Three sentiment analyis tools compute sentiment and emotion for each book of the poem.
- VADER (Valence Aware Dictionary and sEntiment Reasoner) specifically examines sentiments expressed in social media, and is sensitive to polarity and intensity.
- TextBLOB “is a Python library for processing textual data and helps with tasks such as part-of-speech tagging, noun phrase extraction, sentiment analysis, and more”. Here, we measure a text for its polarity (the extent to which sentiment is positive or negative on a [-1,+1] scale) and subjectivity (measured on a [0,+1] scale in which 0 refers to an objective statement and 1 refers to a subjective statement; subjectivity refers to personal opinions, emotions, or judgments, while objectivity refers to factual information).
- NRC measures English words and their associations with eight basic emotions and two sentiments, which combine to yield more complex human emotions. This follows from the work of psychologist and professor Robert Plutchik. The ten attributes are:
- anger
- fear
- anticipation
- trust
- surprise
- sadness
- joy
- disgust
- positive
- negative
To optimize completion time, each model was forced to perform on the GPU via the CUDA Toolkit. The GPU used is NVIDIA GeFORCE RTX 3070. Preliminary tests were done on the CPU: AMD Ryzen 7 3700X 8-Core Processor 3.59 GHz. Final results reported in this paper are those run on the GPU.
Results
Using the tools of NLTK, we can track the frequency of word-use in the poem, which we can use to make a wordcloud. Wordclouds are visualizations of (text) data in which the size of a word represents its frequency or importance in that data. Wordclouds are handy for visualization-at-a-glance, and have the enjoyable consequence of making a report more lively. They are useful for qualitative judgments, but inherently give no numerical information with which to work; a cursory inspection of the wordcloud can give hint as to the subject matter of the text.

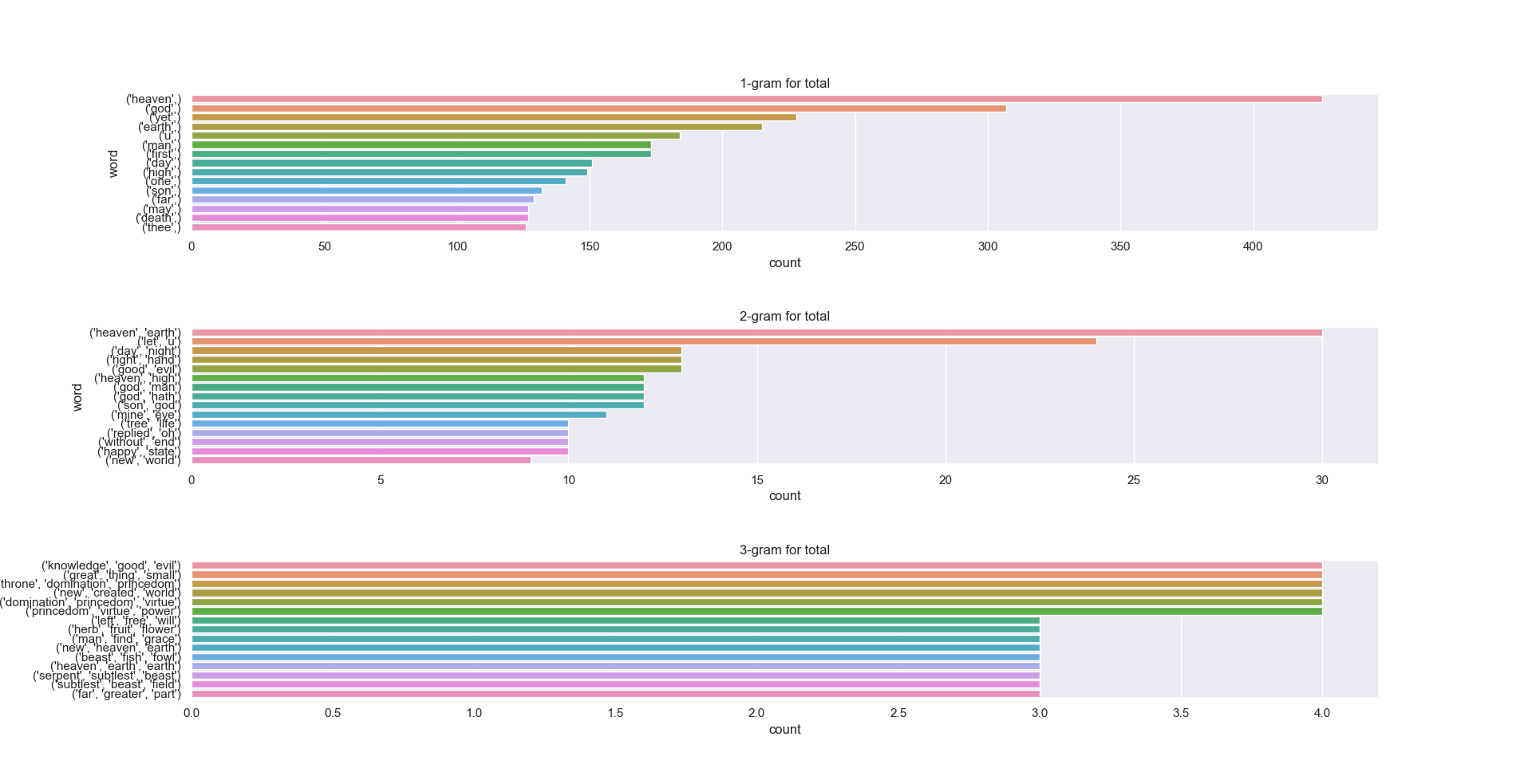
n-gram analyses for n={1, 2, 3} is visualized below. n-grams track the frquency in which (word) tokens appear. 1-grams (monograms) refer to the frequency in which single word tokens appear; 2-grams (bigrams) refer to the frequency in which two word tokens appear together; 3-grams (trigrams) refer to the frequency in which three word tokens appear together. Roughly, such frequencies will follow a Zipf-like distribution. n-grams are useful in that they tell us exactly word distributions (once appropriately filtered). Word pairings are exceptionally useful in many contexts, not limited to sentiment. Reconstruction of broken or incomplete texts, for example, and auto-correct are applications of n-grams. The n-gram distributions are plotted accordingly.
The average word length is represented by a probability density, the values of which may be greater than 1; the distribution itself, however, will integrate to 1. The values of the y-axis, then, are useful for relative comparisons between categories. Converting to a probability (in which the bar heights sum to 1) in the code is simply a matter of changing the argument stat=’density’ to stat=’probability’, which is essentially equivalent to finding the area under the curve for a specific interval. See this article for more details. Here, Milton is fairly consistent in his word-length for lexical words. While attempted to fit to a gaussian, the distribution follows with an average of 5.57 (SD = 0.06).
<img src="/assets/sentiment_pl/vis_data_leng.png" alt="average word length"
Lexical densitity (or lexical diversity) is related as the lexical words of a text (content words such as nouns, adjectives, adverbs, verbs) divided by the total number of words. This relationship indicates the content words per total in a text. This number can be normailzed by using the size of the smallest text (word count 2824 — the length of the shortest chapter) instead of the true total. This allows for a scaled comparison.
Milton tends towards consistency in his lexical inventory, and has a relatively high inventory of lexical items. The range of scores is [0, 1]; higher scores indicate higher lexical density. The average across all books is 0.51 (SD = 0.03) with (min,max) = (0.45,0.57), and the average across all books for the normalized data is 0.56 (SD = 0.02) with (min,max) = (0.53,0.59). Written forms of human communication in the English language typically have lexical densities above 0.40, while spoken forms tend to have lexical densities below 0.40 (Castello 2008). In a survey of historical texts by Michael Stubbs (1996), the typical lexical density of fictional literature ranged between 0.40 and 0.54, while non-fiction ranged between 0.40 and 0.65.
<img src="/assets/sentiment_pl/vis_data_dens.png" alt="lexical density"
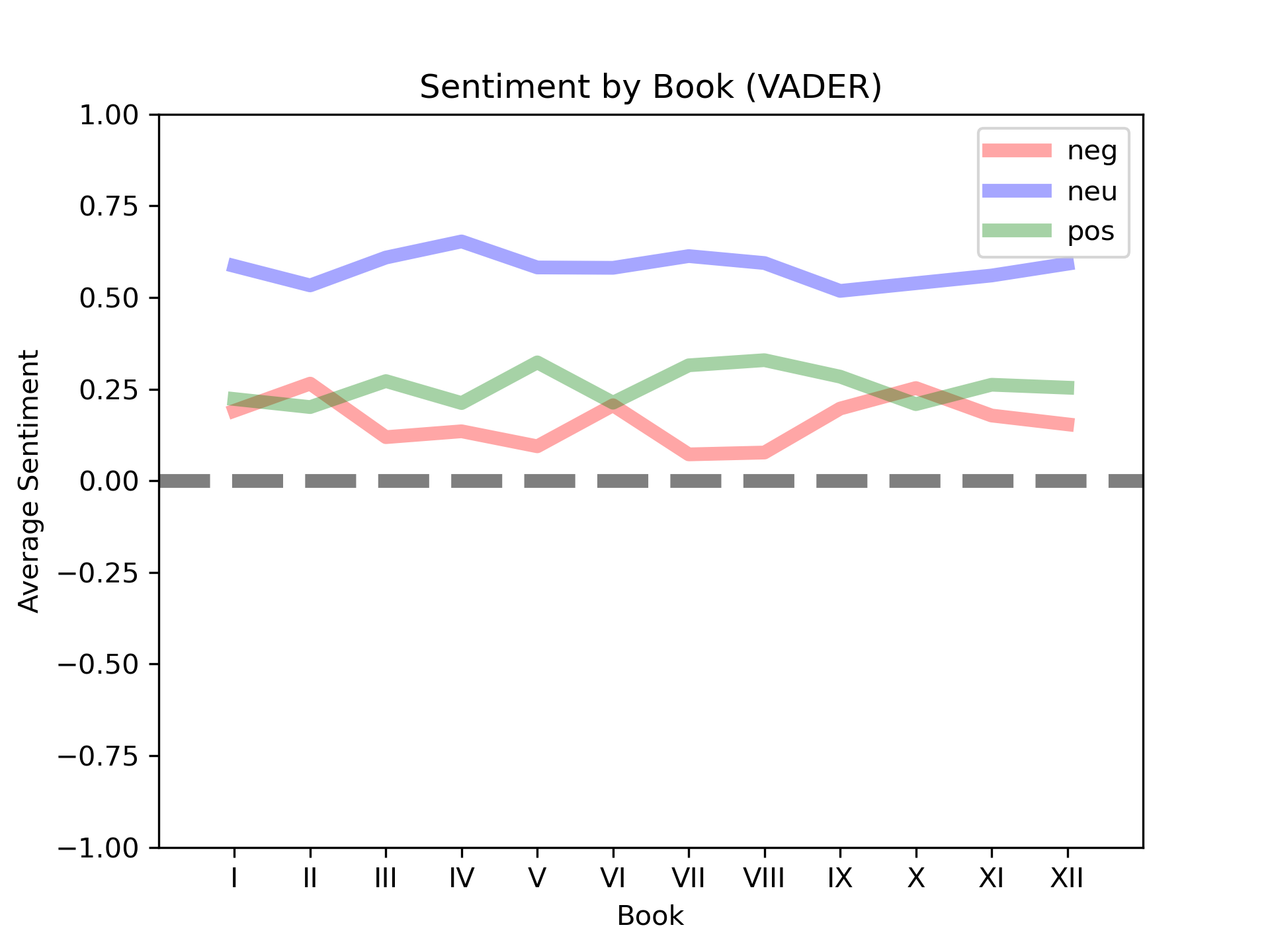
The results of the VADER analysis are given below. The Neutral sentiment (neu; avg = 0.58, SD = 0.04) scores higher above the other sentiments consistently across all books of the poem: neg (0.16, SD = 0.06); pos (0.26, SD = 0.05). Here we face an interesting interpretation of results. Indeed, this may follow from Milton’s style, which is certainly a formal register, or it may be a limitation of the analytical application, given that the language of Paradise Lost is not the intended target for VADER (this is a recurring theme, in that the deliberately archaic style of the work is quite dissimilar to the styles the sentiment analysis tools are trained on).
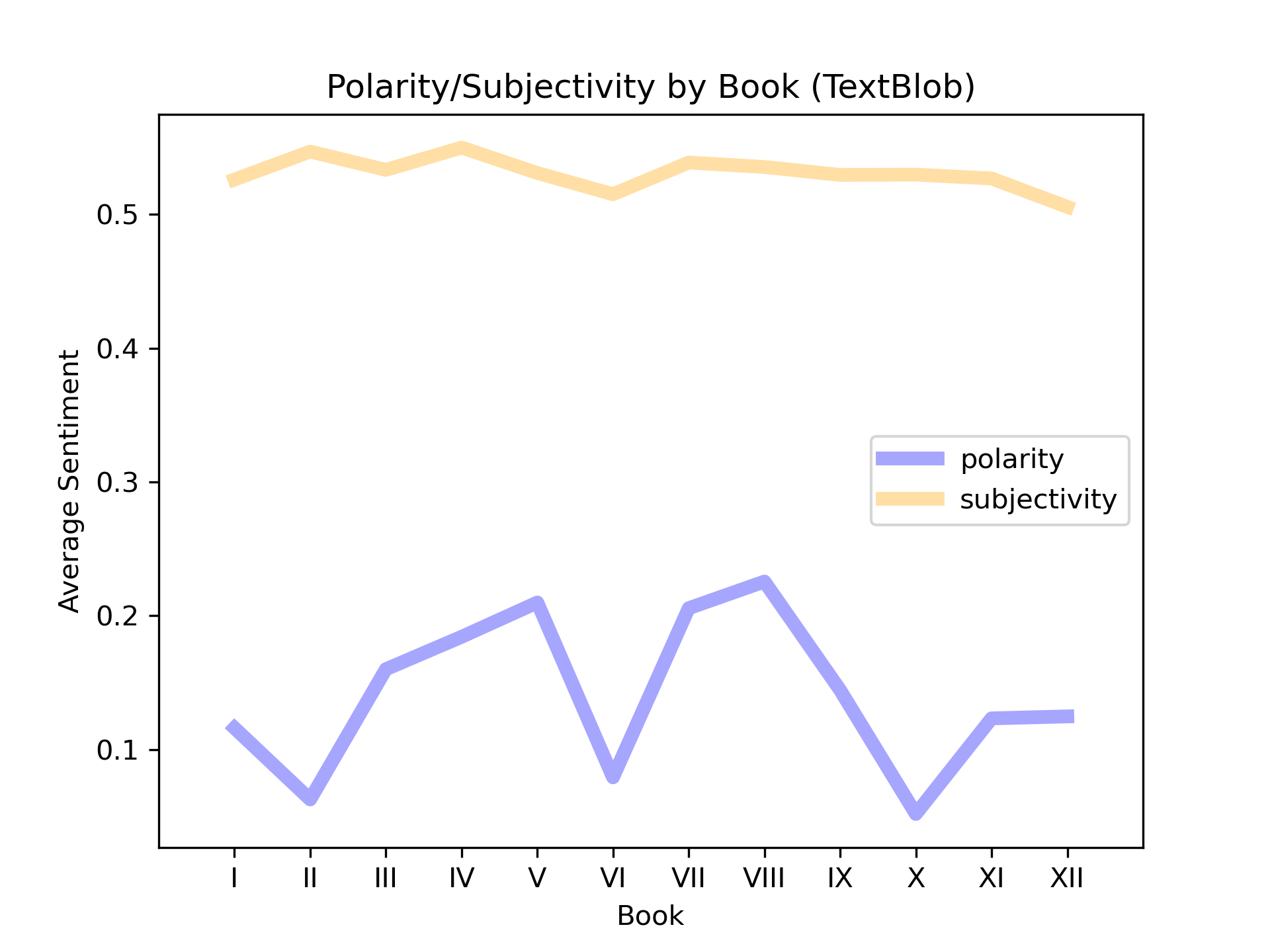
The results of the TextBLOB analysis are given below. We see that the Subjectivity score (0.53, SD = 0.01) is not only significnaly higher than the Polarity score (0.14, SD = 0.06), but is also much more consistent across each book of the poem. The consistency and high scores for the Subjectivity metric indicate a more personal narrative rather than an objective account.
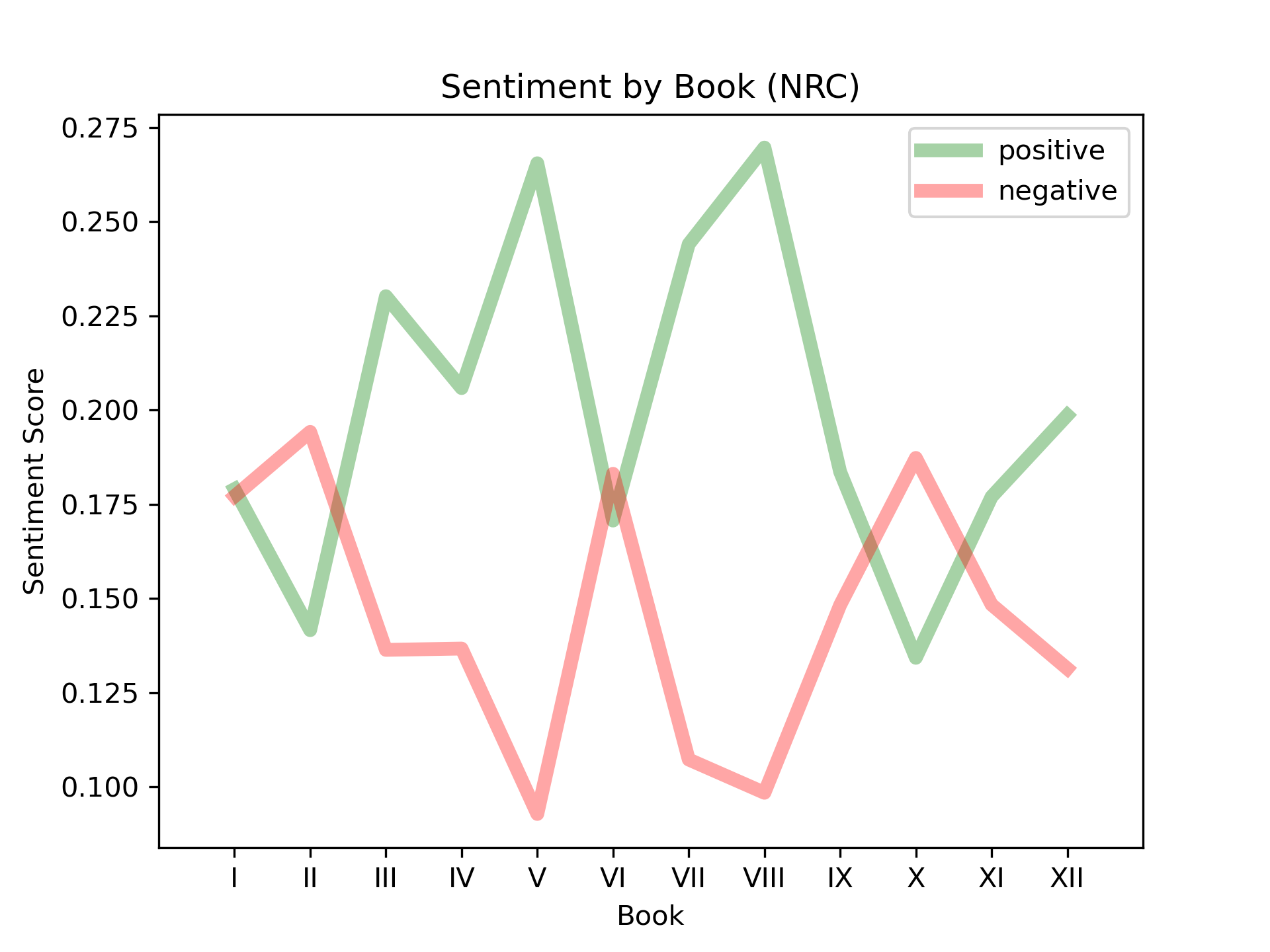
For the NRC analysis, Plutchik describes the attributes in diametric pairs (that is, we consider the positive group (anticipation, joy, surprise, and trust) relative the negative group (anger, disgust, fear, and sadness)). The NRC scores indicate that the poem tends towards a higher overall positive score (0.20, SD = 0.04) than negative score (0.15, SD = 0.03), where the strongest emotions are: trust (0.12, SD = 0.03); fear (0.11, SD = 0.03); anticipation (0.10, SD = 0.02); joy (0.09, SD = 0.02). The lowest scores are: surprise (0.04, SD = 0.01); disgust (0.05, SD = 0.01); anger (0.07, SD = 0.02); sadness (0.07, SD = 0.02).
Discussion
TextBLOB extrema points tend to correlate with intersection points described above in the VADER and NRC analyses, in which minima of polarity scores in TextBLOB correlate with increasing negative scores and decreasing positivy scores in VADER and NRC, and vise versa. These “points of interest” occur in regions Books I to III, Book VI, and Books IX to XI. Books I to III narrate Satan’s new situation after having been expelled from heaven, his resolve to claim the exile and rallying of fallen angels to their new station, and God and the Son of God observing and conversing about Satan’s actions. Book VI narrates the triumph of heaven over the rebellious angels, and Books IX to XI essentially follow the Eden story with an optimistic conclusion.
A practical limitation on this study is as follows: the GPU, while a good GPU, is still not an optimized machine for which to perform ML tasks; the flagship 3090 model is a better optimized GPU for such tasks, and the Apple M1 chip is an additional alternative as it is equipped with an NPU (Neural Processing Unit) specifically designed for ML tasks.
The language of Milton is not the language of Modern English, and so tools for sentiment analysis need to be sensitive to that. Indeed, even cleaning the data needed to be ammended to account for the stopwords of the English used in the poem. As a literary style, poetry invokes imagery, syntactic inversions, similes, and other devices that may obfuscate the machine learning applications to the text.
The extent to which sentiment analyses may be compared itself invites further study. Indeed, comparisons and applications of the two analyses have been featured in various investigations, including two direct comparisons (here and here), as well as a sentiment analysis of The Silmarillion.
Conclusion
Investigated here were three sentiment analysis tools applied to Milton’s Paradise Lost. Across each model, though geared for different aspects of sentiment, scores tend to match such that VADER and NRC trend similarly one with the other, in which intersection points match with the extrema points in the TextBLOB analysis.
Sentiment analysis does not lack for applicability, and there are many apporaches to the problem in NLP, including statistical ML models and neural network ML models. What has been shown here is that each computatinal tool to assess sentiment and emotional attributes tends to match a human’s intuition for such responses in the text. Paradise Lost, while perhaps not a light read, is certainly empassioned with the author’s intended emotional affect.
“Me miserable! Which way shall I fly
Infinite wrath and infinite despair?
Which way I fly is hell; myself am hell;
And in the lowest deep a lower deep,
Still threat’ning to devour me, opens wide,
To which the hell I suffer seems a heaven.”
Book IV, Lines 73-78
Bibliography
Costello, E. (2008). Text Complexity and Reading Comprehension Tests. 49–-51.
Stubbs, M. (1998). Text and Corpus Analysis: Computer-assisted Studies of Language and Culture. International Journal of Corpus Linguistics, 3, 319–327.